Abstract Diffusion models have showcased their capabilities in audio synthesis ranging over a variety of sounds. Exsiting models often operate on the latent domain with cascaded phase recovery modules to reconstruct waveform. It potentially introduces challenges in generating high-fidelity audio. In this project, we propose EDMSound, a diffusion-based generative model in spectrogram domain under the framework of elucidated diffusion models (EDM). Combining with efficient deterministic sampler, we achieved similar Fréchet audio distance (FAD) score as top-ranked baseline with only 10 steps and reached state-of-the-art performance with 50 steps on the DCASE2023 foley sound generation benchmark. We also revealed a potential concern regarding diffusion based audio generation models that they tend to generate samples with high perceptual similarity to the data from training data.
Section 1: Audio Generation with EDMSound
Unconditional Generation Results on SC09*
| Model | Zero | Three | Five | Six | Seven | Eight |
|---|---|---|---|---|---|---|
| Training Sample | ||||||
| EDMSound |
Conditional Generation Results on DCASE2023 Task-7
| Category | Training Sample | EDMSound | |
|---|---|---|---|
| Dog Bark | |||
| Footstep | |||
| Gunshot | |||
| Keyboard | |||
| Moving Motor Vehicle | |||
| Rain | |||
| Sneeze, Cough | |||
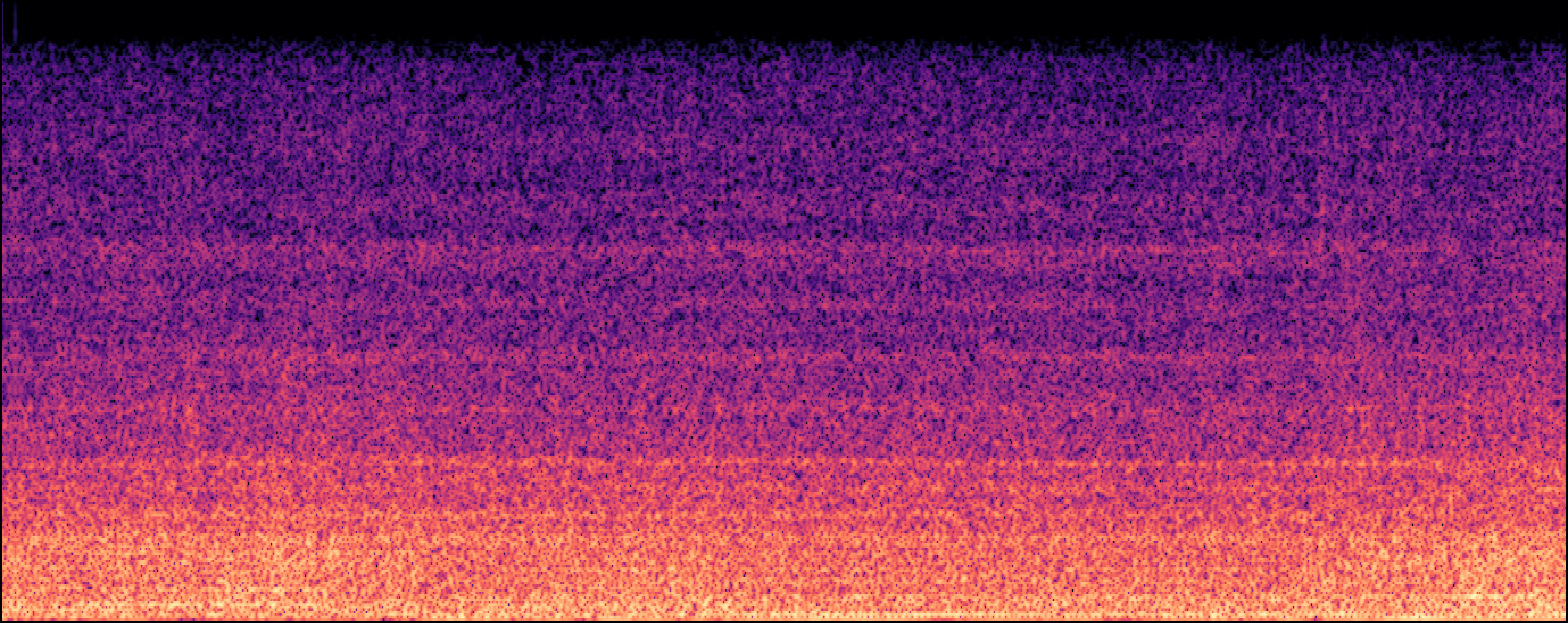
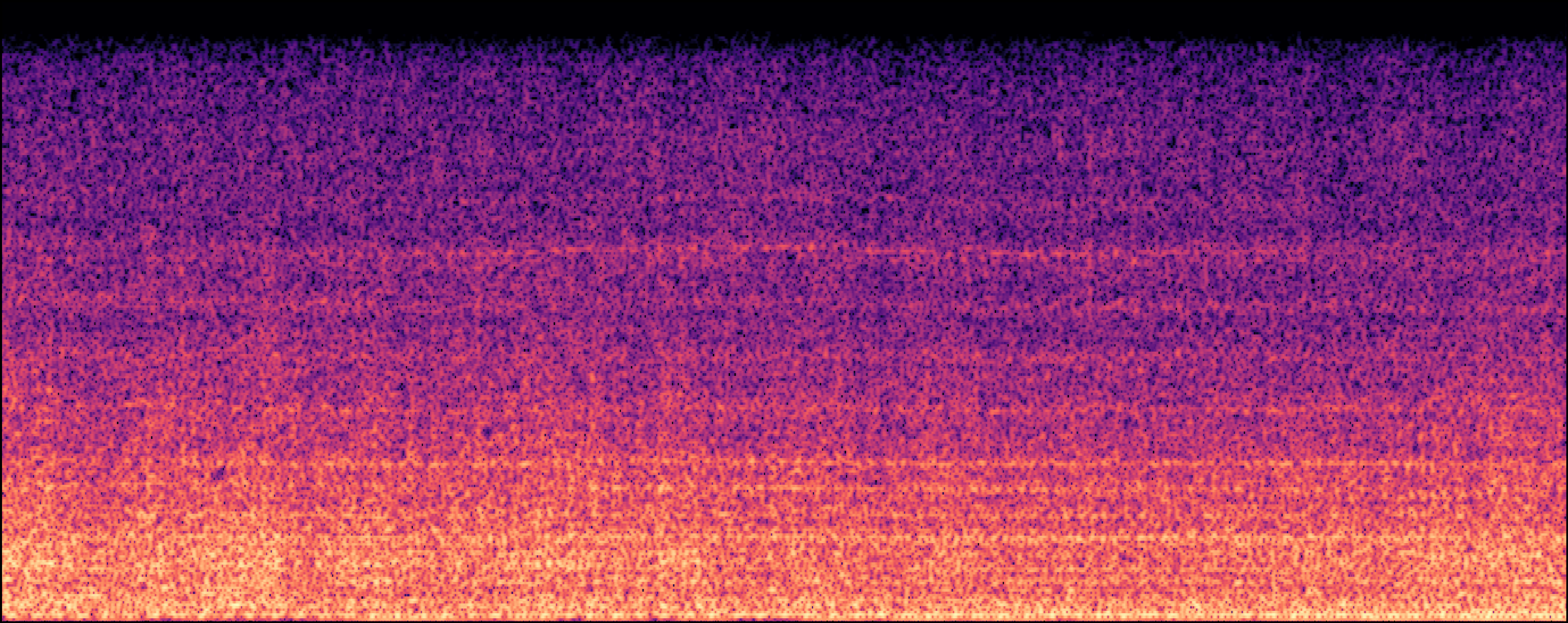
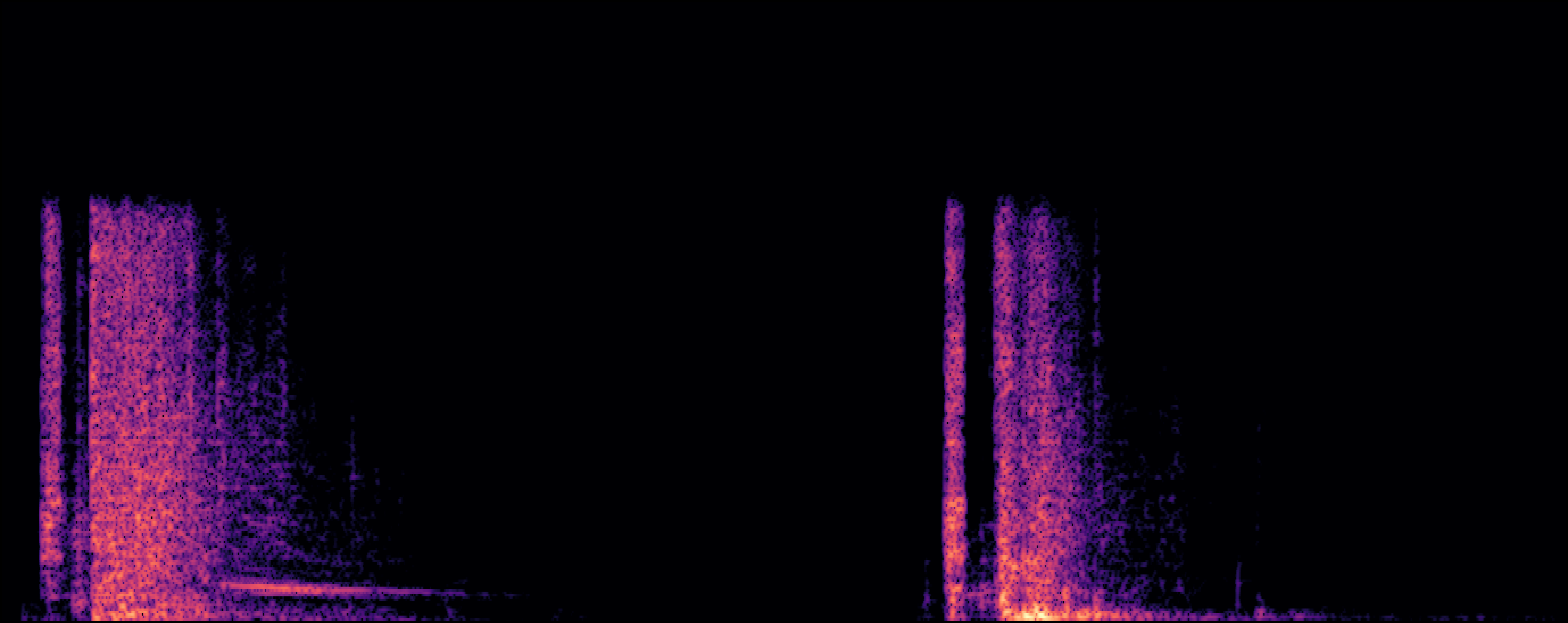
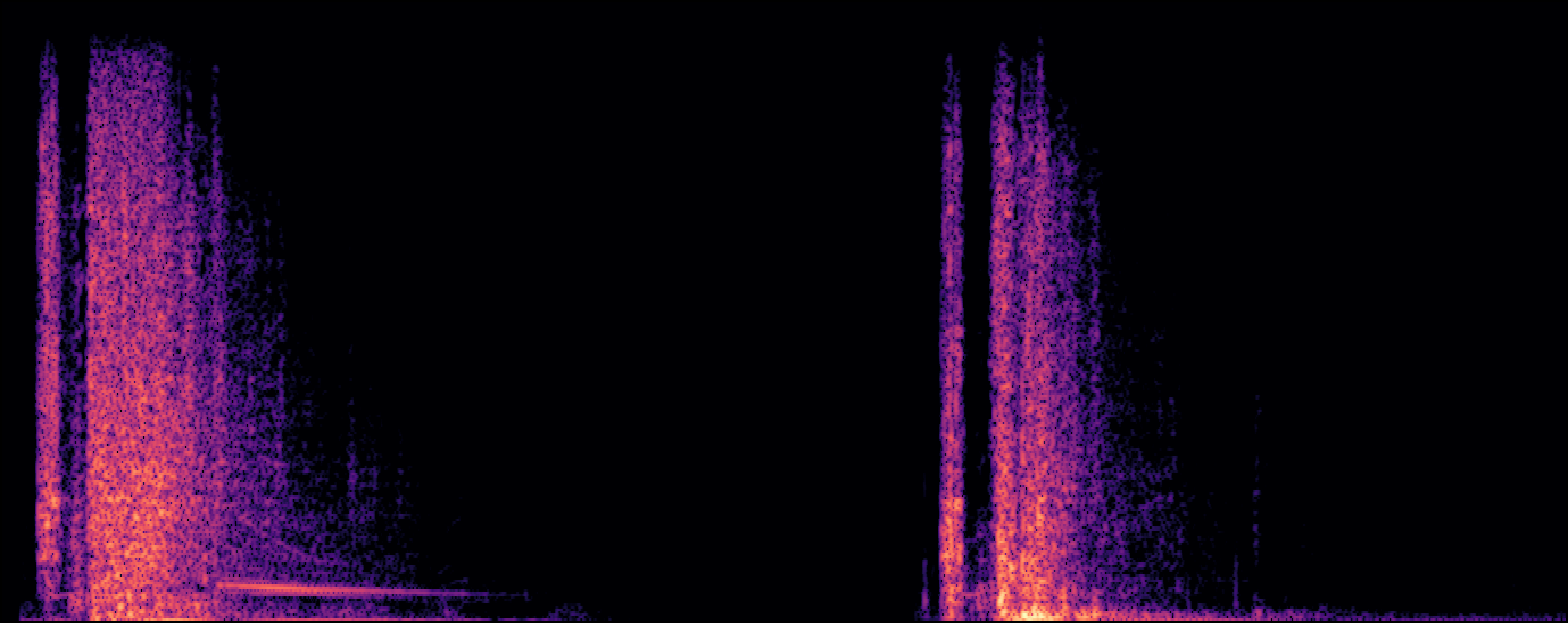
Section 2: Replication Detectoin
| Model | Generated Sample | Top-1 Matched Training Sample |
|---|---|---|
| EDMSound |
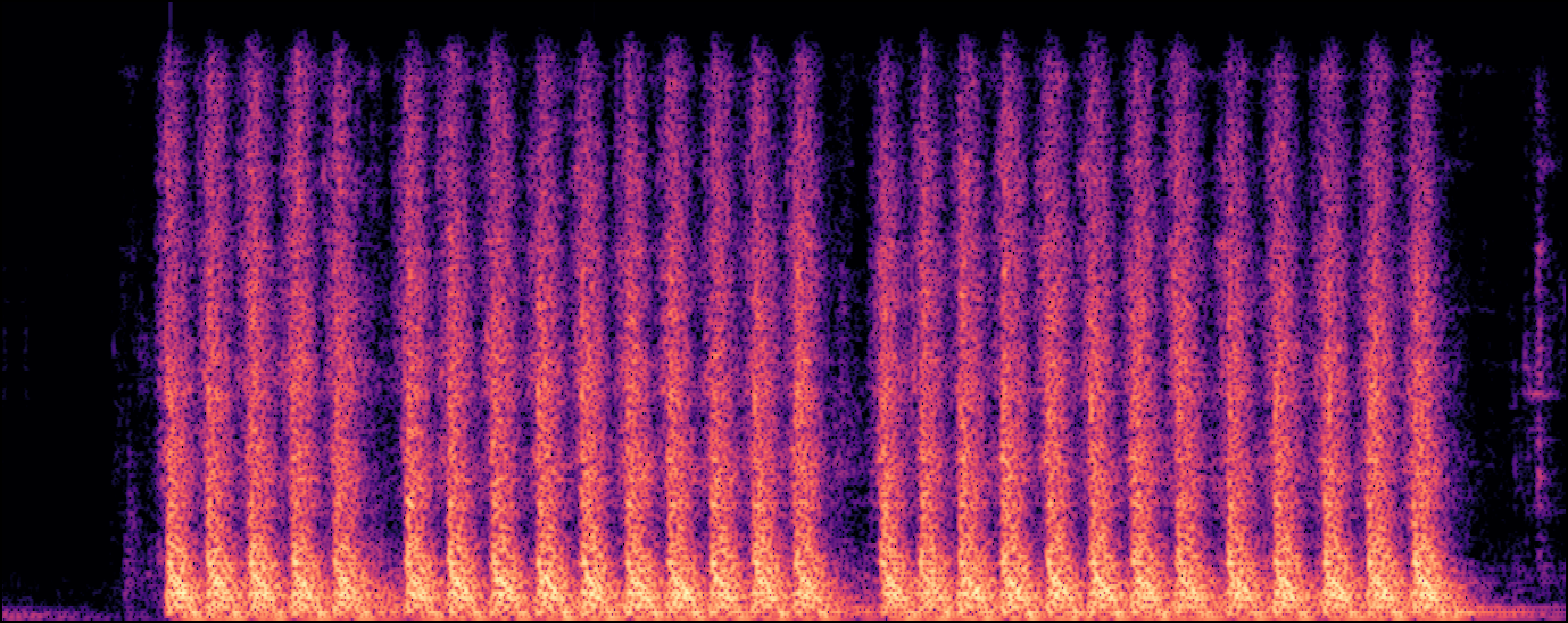
|
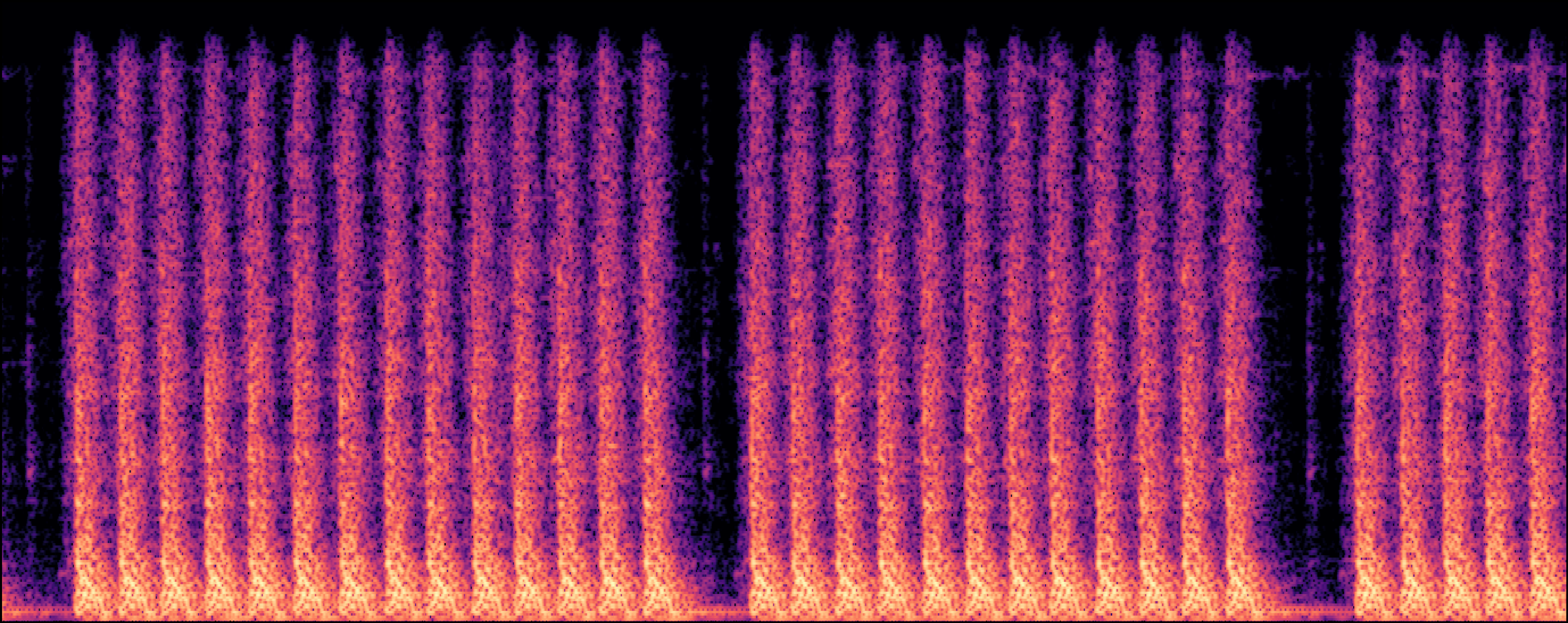
|
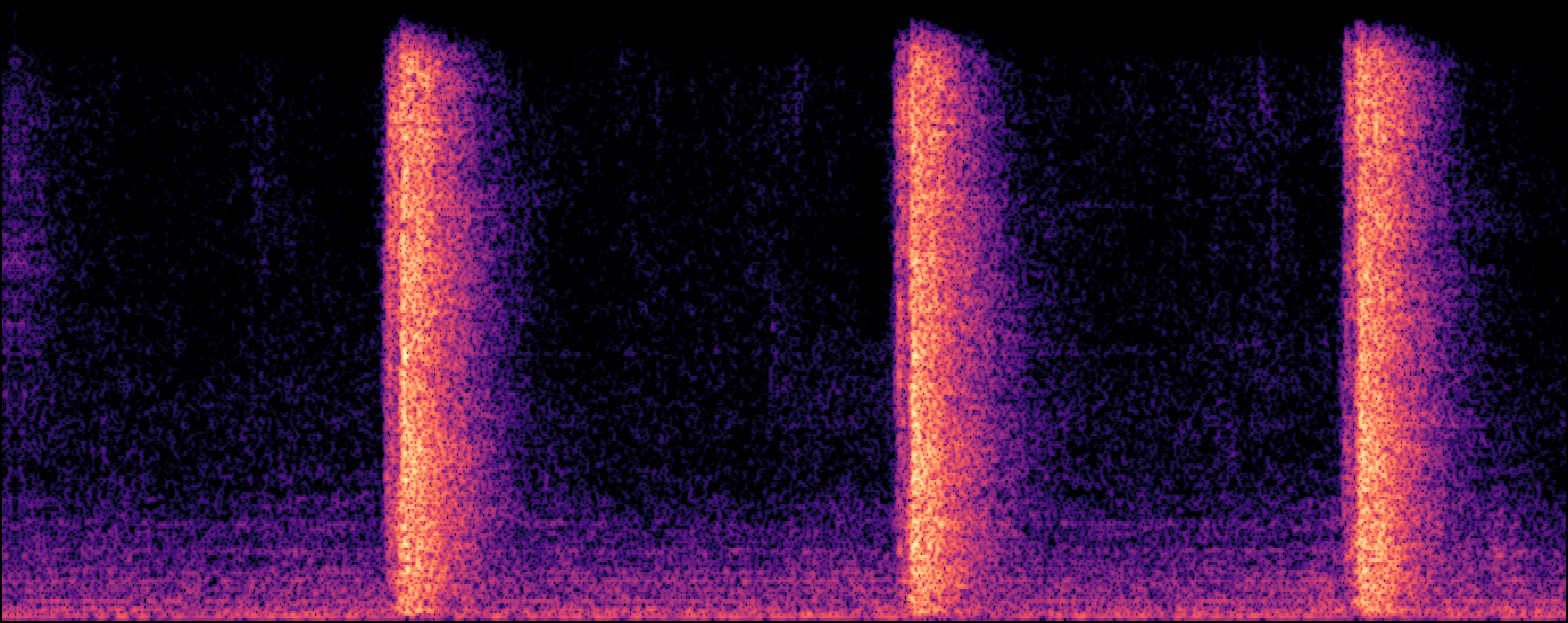
|
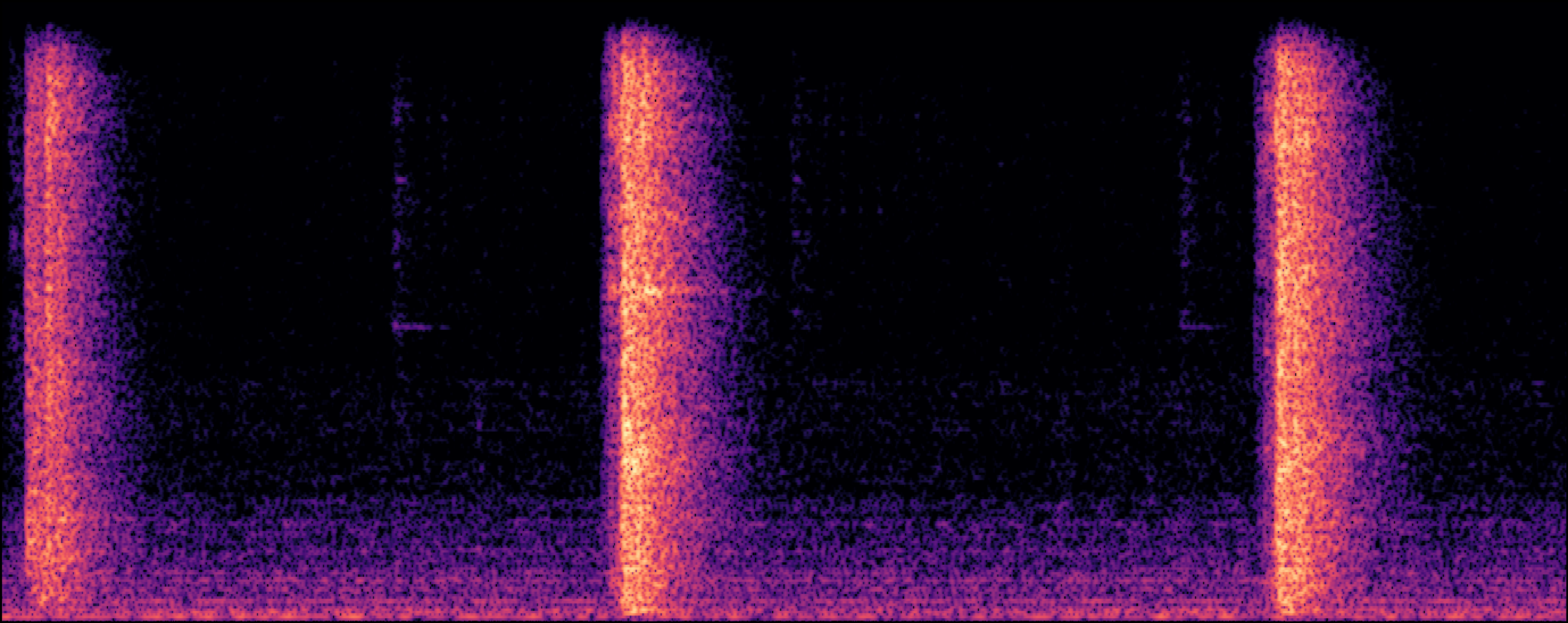
|
|
|
|
|
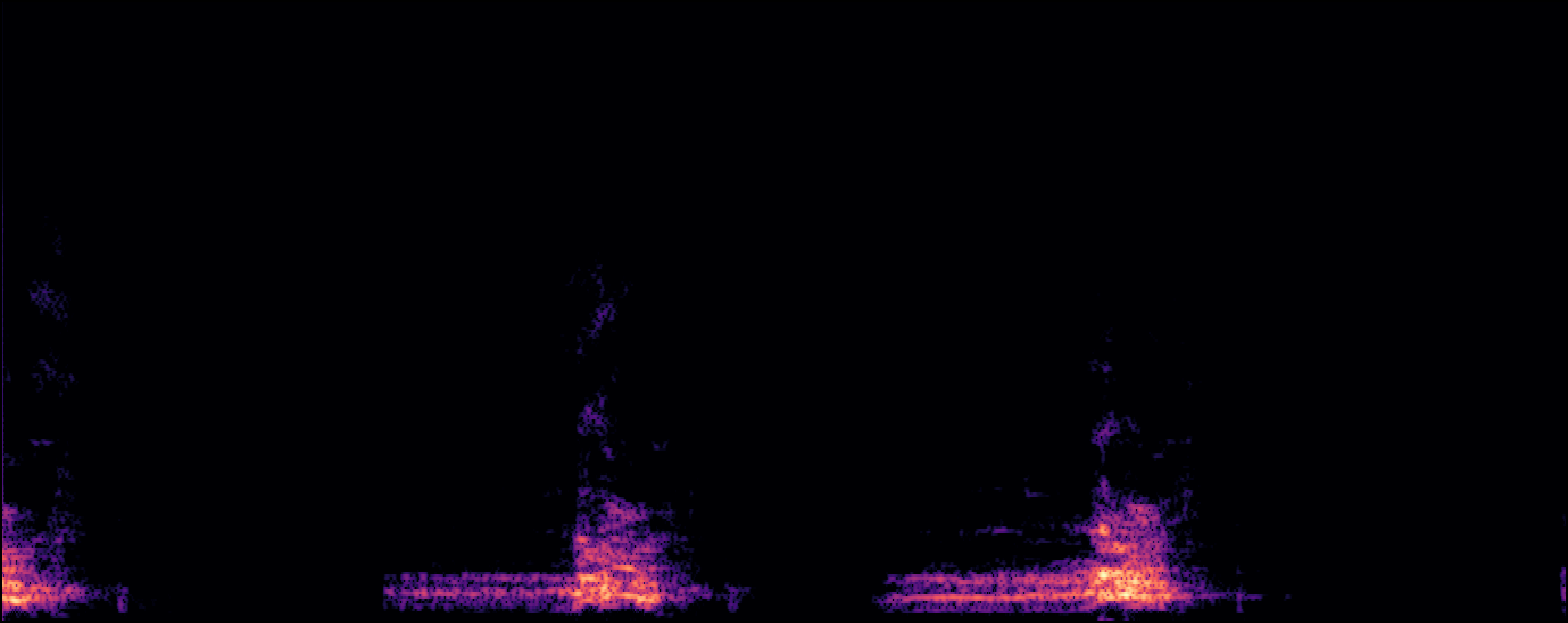
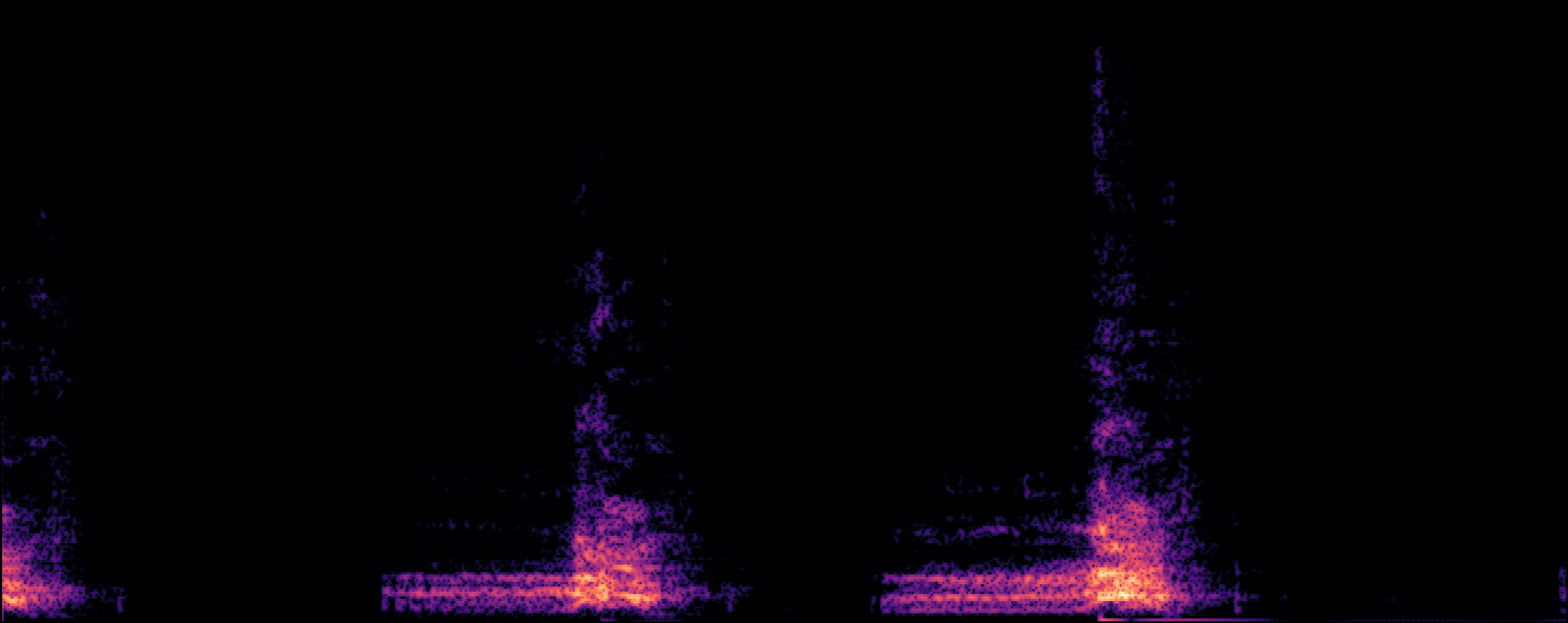
| Scheibler et al |
|
|
|
|
|

|
|
|
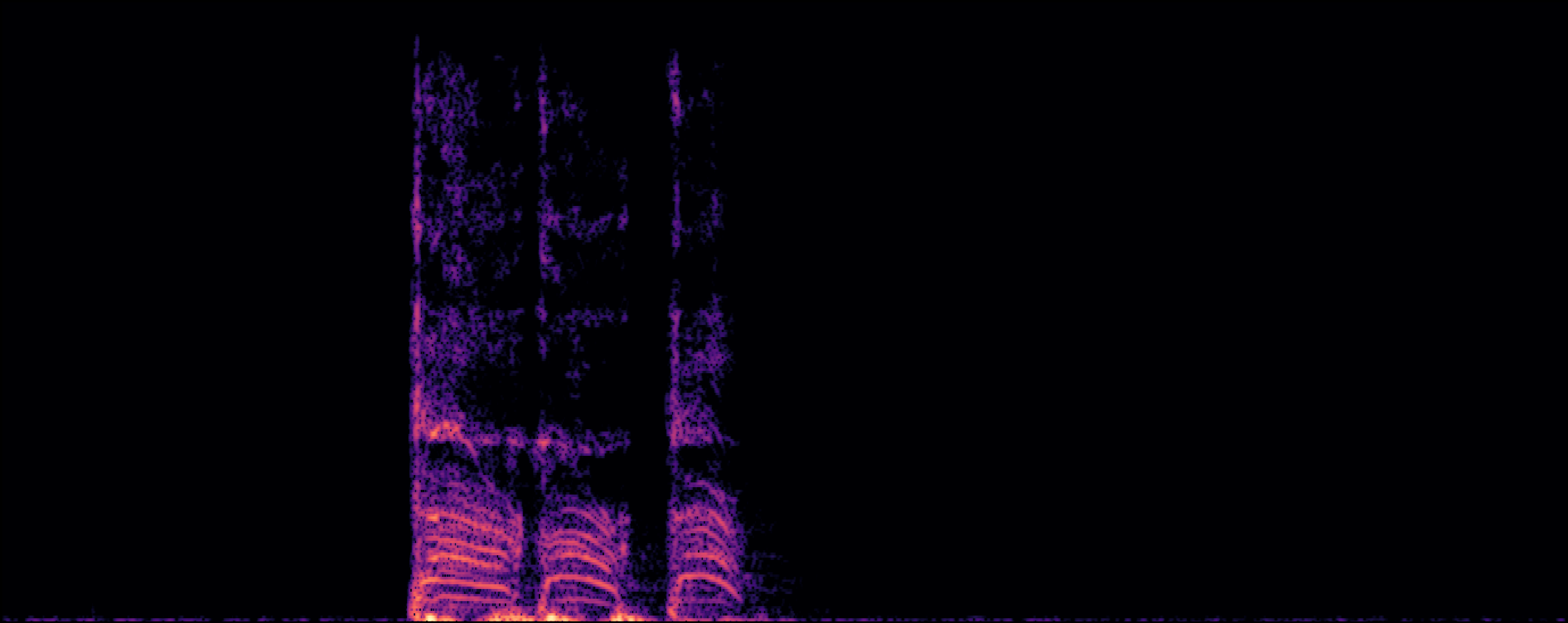
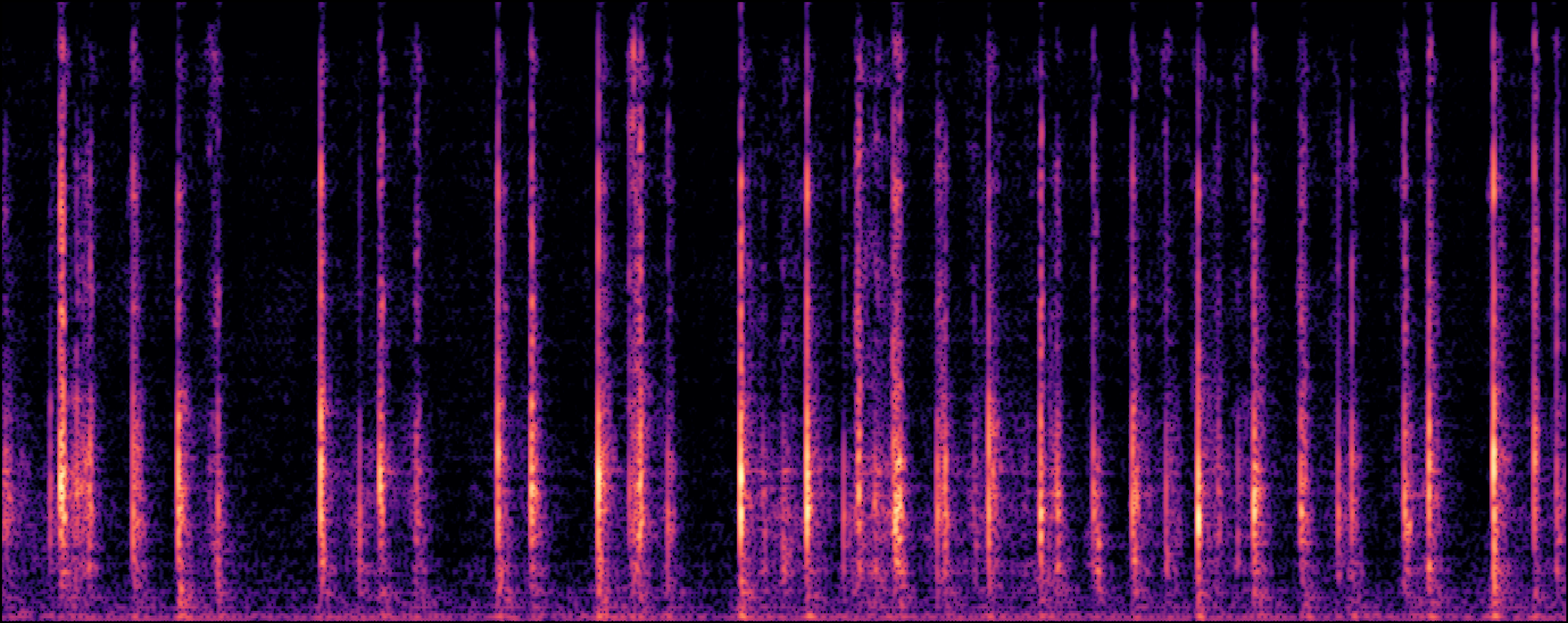
| Yi et al |
|
|
|
|
|
|
|
|
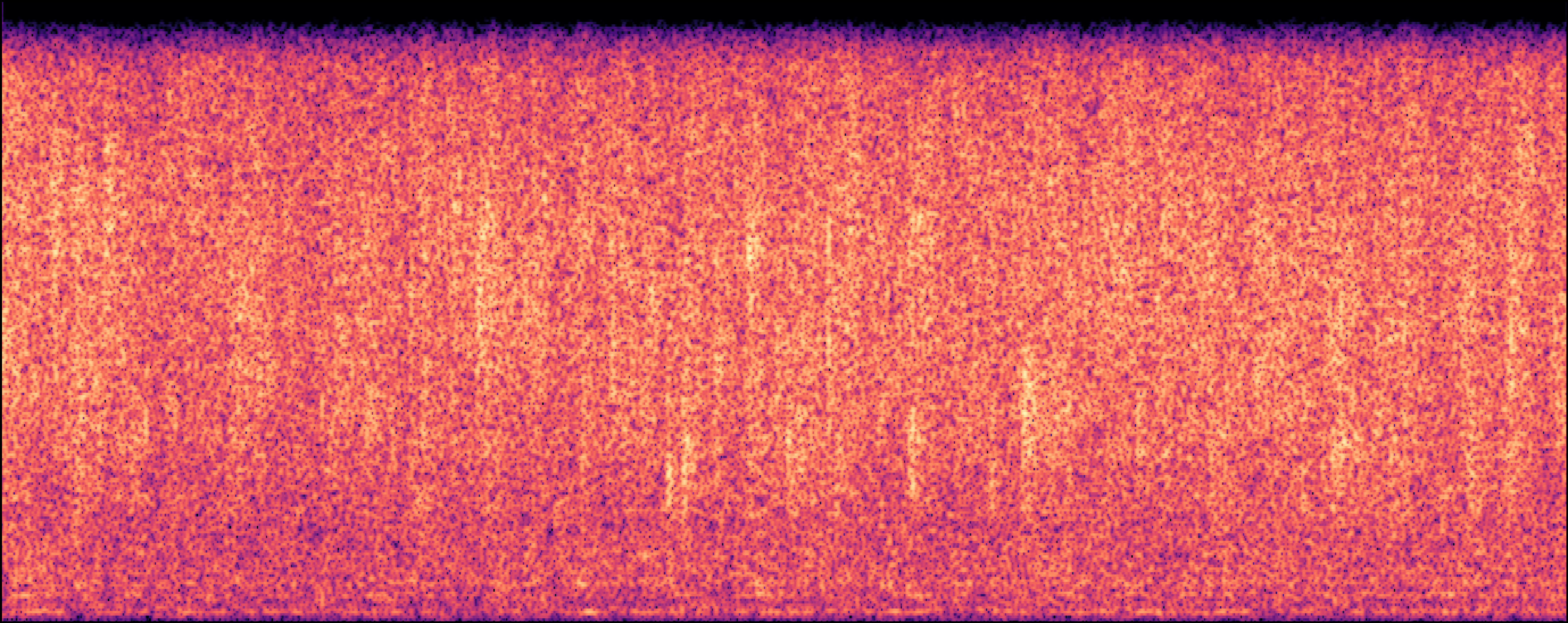
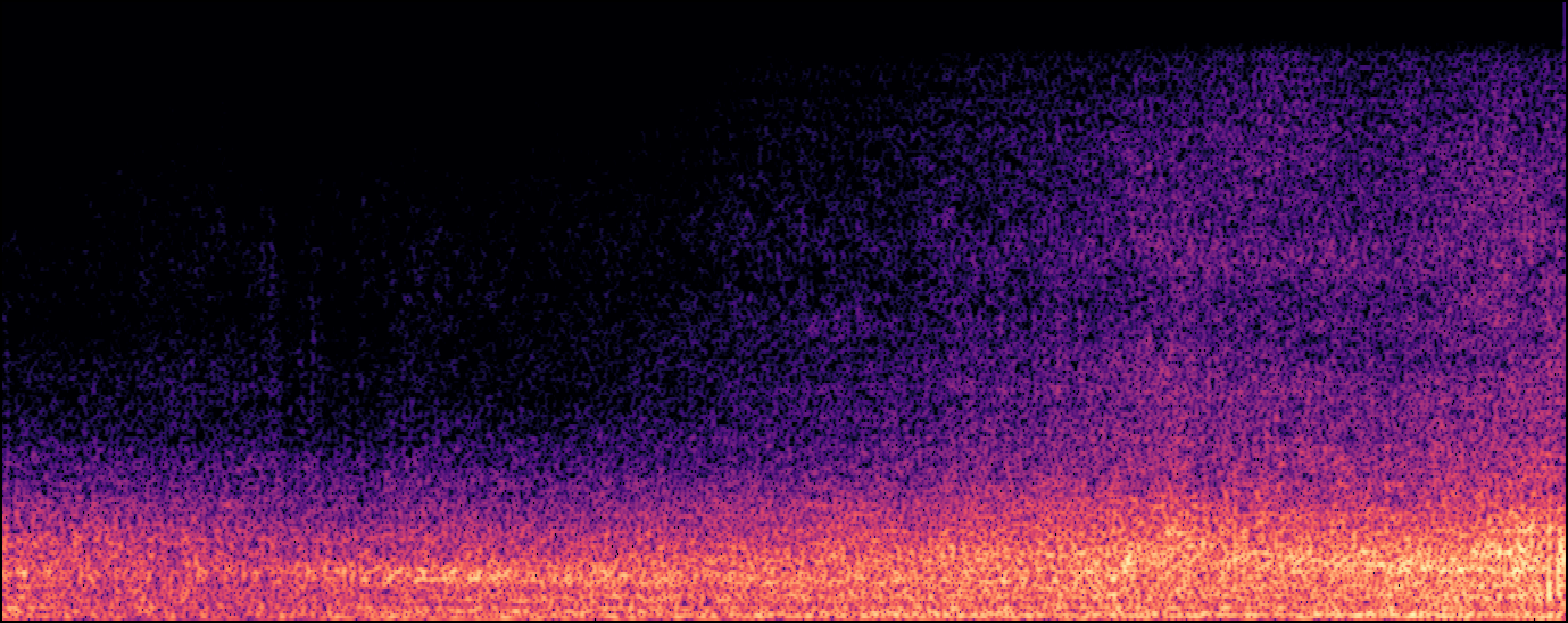
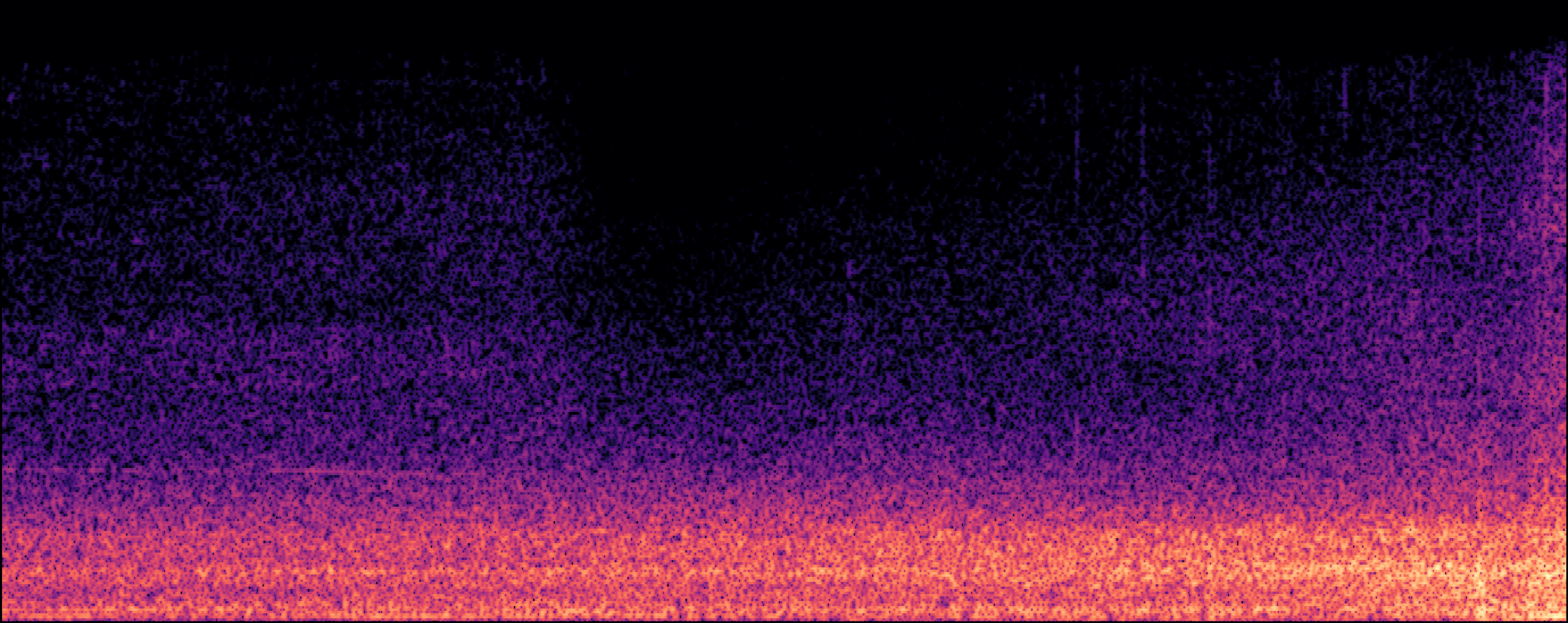
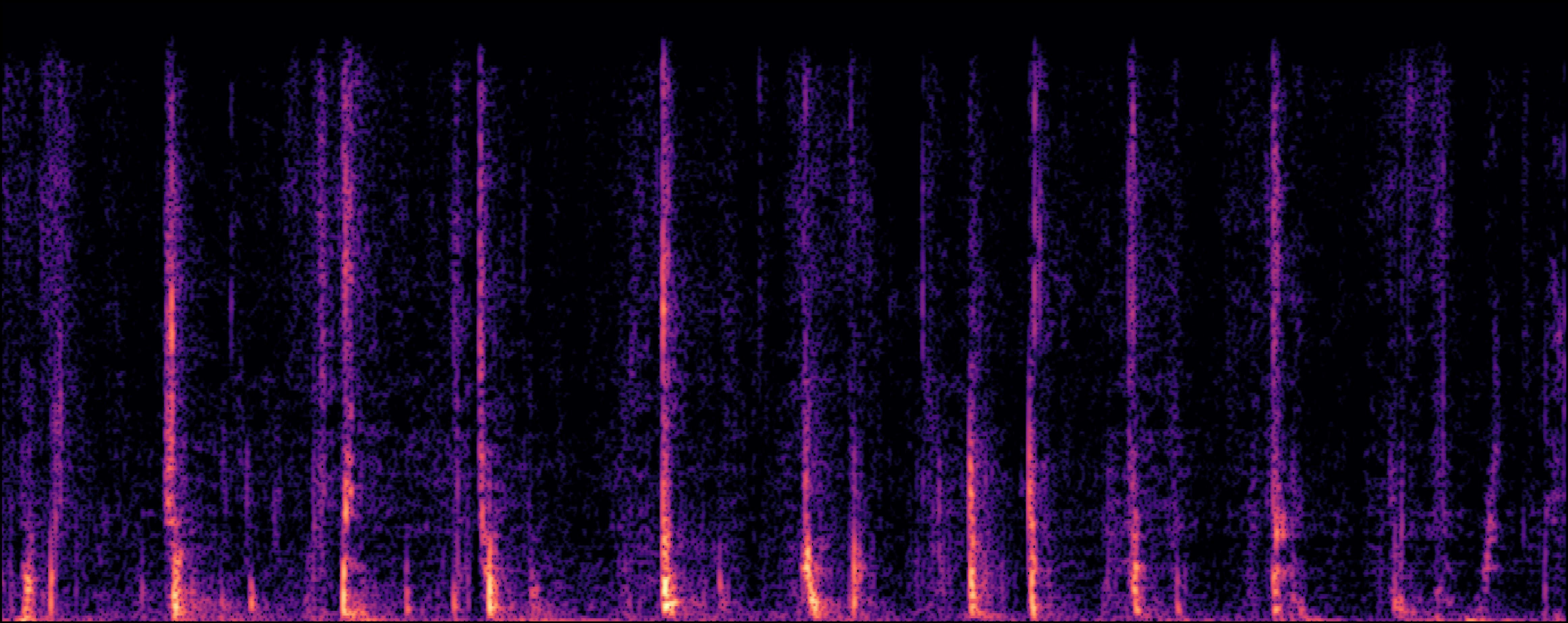
| Jung et al |

|

|
|
|
|
|
|
References
[1] R. Scheibler, T. Hasumi, Y. Fujita, T. Komatsu, R. Yamamoto, and K. Tachibana. "Class-conditioned latent diffusion model for dcase 2023 foley sound synthesis challenge." Technical report, Tech. Rep., June, 2023.
[2] Y. Yuan, H. Liu, X. Liu, X. Kang, M. D. Plumbley, and W. Wang. "Latent diffusion model based foley sound generation system for dcase challenge 2023 task 7." arXiv preprint arXiv:2305.15905, 2023.
[3] H. C. Chung, Y. Lee, and J. H. Jung. "Foley sound synthesis based on gan using contrastive learning without label information." Technical report, Tech. Rep., June, 2023.
[4] Warden, Pete. "Speech commands: A dataset for limited-vocabulary speech recognition." arXiv preprint arXiv:1804.03209 (2018).
[5] Choi, Keunwoo, Jaekwon Im, Laurie Heller, Brian McFee, Keisuke Imoto, Yuki Okamoto, Mathieu Lagrange, and Shinosuke Takamichi. "Foley sound synthesis at the dcase 2023 challenge." arXiv preprint arXiv:2304.12521 (2023).